Home/Glide/Old blog | Donate - Impressum
Jan-31-2005
After procrastinating for an awfully long time, today I've finally packaged up and released the instructions for getting
Need for Speed 3 and 4 to run, kindly provided by Mark Bell. If you're having trouble with these games, go have a look.
And then, I'd like to announce that significant performance tweaks are coming up.
First, the Project64 and Glide64 crowd is going to have to wait a little while longer for the much desired TEXTUREBUFFER extension and (after all these
years ...) multi-texturing support.
The LFB emulation is going to get its major overhaul first, and this time it's an all-out performance kind of overhaul that will hopefully please
people who play games like Jane's F15. These are currently bottlenecked by readback performance more than anything else, especially in high res mode.
I now have a few new tricks up my sleeve to greatly speed up high res readbacks
(*cough*),
but essentially everything LFB related is faster now.
Need benchmarks?
- Carnivores demo, staring into the sun, high res mode, Radeon 9200
0.82b: 7 fps
Current build: 31 fps
- Outlaws demo, start of first level with map toggled on, high res mode, Geforce FX5900XT
0.82b: 26 fps
Current build: 65 fps
The limiting factor in both of these cases is (still) readback performance. But it's obviously a lot better now 
Now, some percentage may still be lost or gained because there are some remaining issues with the robustness of the new solution. Anyhow,
this should end up delivering enough of a performance improvement to finally make high res mode a viable option for every game that runs at all.
MDK's performance index OTOH doesn't care about readbacks at all, it only writes to the LFB. And it's up, too, from 430 to 480 if I play it fair.
But beyond playing fair, I've implemented another optimization for MDK ... don't get this wrong, it's an entirely valid, legal and robust optimization,
but MDK really is the only game that benefits at all. 1100. Same system. No kidding. This will be in.
Dec-21-2004
*cough*
I originally didn't plan to do this but ... well, either noone noticed or noone cares (except for Christiano; thank you!) ...
I have a donation page up. If you like my Glide wrapper and want to encourage development, I'd appreciate if you'd at least
take a glance. Thanks bunches.
I hope you'll have a fun and peaceful christmas. Take care.
Oct-22-2004
Okay, so there was no beta. Hmmmm ...
The fundamental problem was that I just couldn't produce a version that would work correctly all the time. Special games
required special tweaks to the code. And then it occured to me that I just need to make it configurable :-)
That got me somewhat back on track, at the expense of one more option in the configurator. Behold:
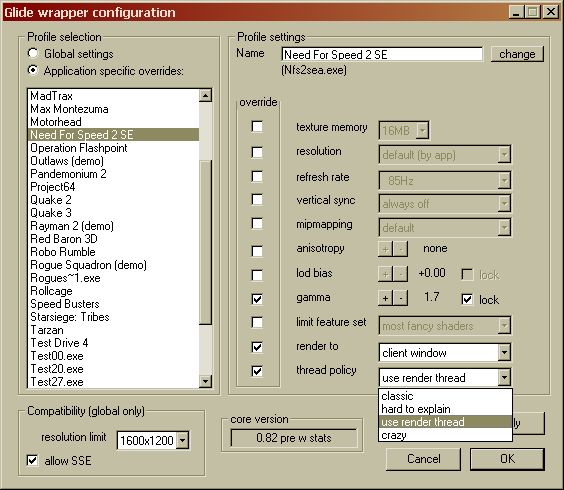
See the "thread policy" thing? This will basically let you choose between old behaviour, much like 0.80e plus a few bug fixes, so that
games that worked with that version aren't broken, and a variety of "new" behaviours, that do multithreading to various degrees. I would
have very much liked to get a "one size fits all"-solution, but as I couldn't, I figure it's good if the new stuff can be tuned, and turned
off. And that shot shows another new nicety: profiles can now be renamed at will. No more figuring out exe names. Go me.
Speaking of the configurator, I know it's clunky, I know it badly needs tooltips and a little glitz. I plan to fix that someday
with a Java based version. I must admit that ATI's CCC inspired this move, in a knee-jerk sort of way. But the "classic" configurator
will be kept up-to-date. The only difference between the two will be visual appearance. The Java runtime environment
is a 15 megs download after all, and I'd be nuts to require a package that large just for my 200k-ish software ...
Oct-15-2004
Yep, I'm still alive, and still chugging away. During the past weeks I've hit some issues of the rather unexpected sort, and
learned about a couple more frustrating aspects of Win32. Won't get into that right now, but I should make an excuse for the
long delay. I'm not satisfied with what I'm seeing here. I might do an officially unofficial "beta" release during the weekend, but
it won't be the recommended version, and it will have significant issues. Just so you know what's going on currently, these are things
the current build does better than 0.80e:
- Need for Speed 2SE (full version) now runs fine
- in-game resolution switching in Dethkarz now works without issues
- Star Wars: Rogue Squadron doesn't crash anymore (but isn't playable, see other issues below)
- textures in Boss Rally are no longer blurry
- automatic mipmap generation now works properly for paletted textures on Geforce cards (but is slower and uses more graphics card memory)
- a fix for the blurry cockpit views in Jane's F15 has been implemented. However, it is currently unknown whether this version
can support Jane's F15 at all.
- Croc now works as advertised (intro and game)
- The "To be continued" demo by Sawtooth Distortion now renders all text correctly.
Things that are worse than in 0.80e:- UltraHLE stutters like mad and stops registering the ESC key after pressing other keys (ie you can't quit properly once you start playing).
- Outlaws stutters
- Need For Speed 2SE demo intermittently hangs for a few seconds (the full version is not affected)
- Diablo II still reacts to the Windows key, but not by minimizing. Instead, it loses (mouse/keyboard) focus. That's worse IMO.
- Robo Rumble doesn't register mouse clicks/key presses. No way to play, no way to quit.
- General performance in CPU limited situations is reduced. Eg Unreal I intro flyby benchmarks are down by roughly 10 per cent on my system.
Other issues:- Speed Busters doesn't register mouse clicks. You can't start any race, you can't use the menu, you can't even exit properly.
- Star Wars: Rogue Squadron doesn't register key presses except for the arrow keys and backspace/del. You won't be able to create a player profile, so you can't play.
- Rollcage still crashes
- Max Montezuma still doesn't work
As I was occupied with this basic Windows interaction cruft exclusively for the past weeks, I unfortunately didn't get around to
implement any rendering improvements from my "roadmap". Even the most miniscule change to Windows integration can render meaningless all
testing done before the change. This is not my idea of making progress, and I hope I'll get over that hill quickly.
Sep-20-2004
Oh well, the gotchas of library programming ...
When using a single processor machine, and one of your threads is waiting for another thread to do some work, you need a way to tell
the thread scheduler to switch to that thread, so that it actually gets anything done.
As it turns out, Windows' sync primitives not only trigger thread switches all the time, even if you don't want them to, but they are
the only reliable way to switch threads at all. During the research phase calling Sleep(0) did the job perfectly. Put the
current thread to sleep, so that the thread scheduler starts some other thread, and hopefully it will be the one we're actually
waiting for. Worked fine for the vast majority of games I tested, but somehow produced severe stuttering and extremely low performance
in a handful of other games. And then I found out why.
Sleep is specified to work in a truly interesting way:
"A value of zero causes the thread to relinquish the remainder of its time slice to any other thread of equal priority that is
ready to run. If there are no other threads of equal priority ready to run, the function returns immediately, and the thread
continues execution."
Why, oh why? Who designed this?
*shakes head*
So Sleep stops working, if the game played around with thread priorities. Great! Any other options? Ah, there's
SwitchToThread, which sounds very promising.
The huge problem with this function is that it isn't available on the Win9x branch. The small problem is that:
"The SwitchToThread function causes the calling thread to yield execution to another thread that is ready to run on
the current processor. The operating system selects the thread to yield to."
Who designed this?
*shakes head*
So, had that brilliant person who originally designed the Sleep functionality not tried so hard to be clever, the result could have
been actually sensible, and I could stand by my word and not use Windows' sync primitives. Guess what, the plan had to change.
/rant
On a more positive note, Need for Speed 2SE runs. Perfectly. Yay.
Expect a release Real Soon Now.
Sep-18-2004
Note to self: must make more regular use of the blog.
I did it, yesterday. The wrapper is now fully separated into a frontend and a backend, which runs in an extra thread. Both
parts are connected by a asynchronous read/write FIFO. There's also an asynchronous memory manager to shove extra data chunks through
the FIFO, in cases where it's hard to determine up front how big these chunks are going to be (mostly vertex buffers and index buffers).
There was the usual fallout of crashes and failed assertions, but it's coming along nicely. Hopefully, very soon now, this will allow
smooth sailing in most of the "tough" games, like Need for Speed 2, Rogue Squadron, Rollcage et al.
The bad news is that performance will be down. I'm currently at about 25 per cent slower than with previous versions.
The good news is that it could have been worse. I've done a lot of research on this thread communication thing, and I think I made
all the right choices. I don't use Windows' built-in thread synchronization primitives, with the notable exception of
"critical sections" because I knew all along that they are failed designs and would just slow me down.
For the technically inclined who might wish to object to or question that statement, the fundamental flaw with Windows' sync prims is
that every event signal implies an immediate thread switch. You can't circumvent this. This makes the technique useless for
asynchronous comms, because a)your sender thread will have a hard time to "run ahead" by a significant amount, it will always be
suspended immediately after signaling that a new packet is available to the receiver, b)your receiver thread will have very few data
packets to work on, most of the time, and will just quickly go to sleep, either because it runs out, or because it signals free
FIFO space to the sender (see point a), and c)consequently, there'll be extreme pressure on the thread scheduler.
The thread scheduler manages about 650k thread switches per second on my Athlon XP2400+. Interestingly enough, this figure exactly
fits the performance limitations of Microsoft's own DirectX. In .NET, they circumvented the problem by making thread communication
going through network sockets, but this is really a very ugly hack that just avoids the issue of misdesigned sync primitives
instead of fixing it.
*cough*
And I already have that async mem manager. It's still a bit too slow, but it's reliable. It just works. A lot of the overhead
is in there, so I have a good idea on where to concentrate tweaking efforts.
On a related note, the next version will fix the blurry textures in Boss Rally.
And I had a nice idea for the framebuffer readback speed issues that plague some very popular classic flight sims. You know, as I
always said, the root cause is that neither ATI nor NVIDIA ever (until the Geforce 6, that is) bothered to fully utilize the downstream
bandwidth provided by the AGP, and instead insist in their marketing material that more than ~200MB/s just isn't possible with AGP
and you'd need to wait for PCI Express.
I have a Wildcat VP AGP4x card here that nicely disproves this nonsense with roughly 700MB/s of actual delivered downstream bandwidth. Ha!
If you want to run these games faster, and have the money to burn, the most obvious and immediately available solution is to go out and
buy any Geforce 6 series card. Those are mucho fast at reading back pixels. Almost on par with the Wildcat VP.
My idea, to finally get to the point, was to avoid the "read everything back" procedure when a game locks the framebuffer for
reading. The wrapper does so, because it cannot know which parts of the framebuffer the application is actually going to
read. It may be a lot less than the whole buffer, sometimes just a single pixel, sometimes nothing at all.
The "correct" way for an application that needs only a few pixels would be using the grLfbReadRegion entry point instead of locking the
whole buffer. But it's too late now to fix those old games. And that's basically the whole problem.
Inspiration came in the form of memory exception handling. If, instead of getting everything prepared immediately, I just let the
application try to read from an empty "guard page", Windows will roll its eyes and throw an exception. Without further precautions,
the application would just crash. But if I catch that exception (which is a bit quirky, but possible), I also get to know what part
of the framebuffer the application wants to access, and can, still in the exception handler, read back just that part.
This will likely not make it into the next release, but it looks like a nice solution and I'll definitely go for it. If it
turns out to actually work, you may look forward to healthy improvements in Jane's F15 et al. Now wouldn't that be great?
*manic chuckle*
Aug-12-2004
I've managed to reproduce what I think is the cause for blurriness in Jane's F15 cockpit views. Under certain
circumstances in high res mode, the current framebuffer is read from the card (and downfiltered in the process, because
the application expects e.g. a 640x480 buffer, not 1280x960) and later written back. This causes some problems with points.
Depending on the coordinates of the point primitives, points can "smear", i.e. they blow up to twice their intended size
and get dimmer as a result of the downfilter/writeback sequence.
I've written a minimal Glide app that renders some points and locks the buffers, and I encountered the problem. It has
been fixed in the current code base by forcing all points to lie exactly on pixel centers. The next release (whenever) will
have this fix.
Jul-31-2004
In all fairness, I've noticed that automatic mipmap generation doesn't work on Geforce cards for paletted textures (tested on
an FX5700 with FW61.76). The textures come out corrupted. So this "workaround" would benefit both ATI and NVIDIA users. NVIDIA
users will lose hardware palette support in the process, though, if automatic mipmap generation is activated. I.e. auto mips
and hardware palettes will become mutually exclusive.